Menu

.webp)
Every transaction on Aztec costs gas, and gas on Aztec works in two ways: public or private. This article covers how gas is paid, why it has a public and a private mode, and how you handle it whether you're working through an app or a browser extension wallet.
Gas on Aztec is known as Fee Juice and is used to pay for transaction costs. This is the same as $ETH on Ethereum. Some apps will handle transaction costs for you under the hood, but if you are using a browser extension wallet, you will not be able to send transactions without it. Fee Juice can be obtained by bridging the $AZTEC token on Ethereum to the Aztec Network L2. This means that under the hood, all activity that happens on Aztec is underpinned by the $AZTEC token bridged into the network. Some bridges like Shield (by human.tech) handle this for you, allowing you to allocate a portion of your bridged transaction to convert into Fee Juice and land in your wallet automatically.
Assets and transactions on the Aztec Network can be either public or private. If you bridge publicly, your tokens will arrive as public, traceable tokens visible to all. Privately bridging, on the other hand, will give you private assets that are visible only to you. These assets can then be sent privately to another user or wallet without ever revealing who you are, what tokens were sent, how many, or who the recipient is.
Like tokens on the Aztec Network, Fee Juice (gas) can also be public or private. The reason for this is that even if what you are sending is private, the gas you spend to execute that transaction could still be visible if you are using public Fee Juice, potentially revealing transaction patterns and activity. Private Fee Juice keeps your entire transaction footprint hidden. When you send a private transaction, you can use private Fee Juice, and when you send a public transaction, you can use public Fee Juice, which means your transaction costs are always aligned with the type of transaction you're making.
Aztec has native fee abstraction, which means apps could let you pay for transactions in any token you want, or cover your fees entirely. Apps like Nyx may choose to cover part or all of a user's transaction costs, or allow you to pay in tokens that are convenient for you. This means you will most likely never see Fee Juice in an app; instead, you'll pay in whatever makes sense for what you're doing, on your terms. Similarly, you might never even see an Aztec wallet at all, because the app itself becomes your interface that you connect to using your MetaMask wallet.
If you're using a browser extension like Azguard, you'll manage Fee Juice directly in your wallet alongside your private and public balances, converting between tokens as needed to cover transaction costs.
When you bridge tokens in, you'll need enough Fee Juice to cover the cost of your first transaction, then you'll need to monitor how much Fee Juice you have available to make transactions. Browser wallets will allow you to send either publicly or privately to other users and will default to using either public or private Fee Juice depending on the type of transaction. Both private Fee Juice and public Fee Juice will appear by default in your token list.
How you handle Fee Juice depends on where you're transacting: apps can abstract it away entirely and let you pay in any token, while a browser wallet like Azguard puts it in your hands to manage across public and private balances. Match your gas to your transaction, keep private activity private down to the fee, and you move on your terms.
The Aztec Network today activated Alpha V5, a major protocol upgrade passed by token-holder governance and executed onchain. Alpha V5 reduces private-transaction proving times by more than 2x compared to the previous version, lowers the cost of a fully private transaction by roughly 50%, resolves the critical issues found in V4, and sees the first wave of apps go live. Users can now send private transactions and earn yield on Aave simply by connecting their Ethereum wallets on Nyx, bridge from Ethereum to Aztec using Shield or TRAIN, privately collect NFTs on RavenHouse, or play Dark Forest Aztec, a hidden-information strategy game in a universe that lives entirely onchain.
"Alpha V5 continues Aztec's work at the frontier of client-side proving, with cryptographic breakthroughs that cut proving times by more than half this release," said Zac Williamson, Co-founder, Aztec Foundation. "We believe Aztec is now the fastest system in the world for proving a fully private transaction entirely on a user's own device, and every release moves the industry closer to private transactions at public transaction speeds."
As the only decentralized privacy L2, Aztec is the credibly neutral privacy layer for Ethereum. Aztec allows anyone to write smart contracts that include both private and public aspects – every private transaction is proven on the user's own device, so no operator, sequencer, or intermediary can see the data. The Alpha V5 proving improvements come from cryptographic advances that make this client-side proving faster than any prior release. The network remains in alpha, but with V5 it is ready for teams to begin building and deploying applications.
Making private transactions practical comes down to how quickly a proof can be generated on a user's own device, without offloading that work to a server that would learn what the user is doing. On Alpha V5, proving a private token transfer natively now takes approximately 2.5 seconds on a consumer laptop, down from 5.2 seconds on V4, and about 6.8 seconds in a browser, down from 12.5 seconds. Across every measured transaction flow, client-side proving times improved by approximately 2x compared with V4.

Alpha V5 lowers ECDSA signature-verification cost by approximately 2x, speeds up Poseidon2 hashing by approximately 3x, and reduces the protocol circuit gate count by approximately 50% (gate count is the number of individual operations a proving circuit must perform, and it is the main driver of how long a proof takes to generate). Each of these lowers the amount of work a device performs to prove a transaction, and the reduction in gate count in particular compounds across every proof the network generates.
Alpha V5 launches the first wave of apps on a network where privacy is built into the protocol rather than managed by an operator. On other networks that claim privacy, transactions still pass through an operator or node that reads them in plaintext, or depend on a viewing key that a third party holds, so users rely on someone else to protect their data and to decide when it gets disclosed. On Aztec, every private transaction is proven on the user's own device, so the app, the sequencer, and any operator never need to see the underlying data. Nyx is one of these apps, allowing users to privately send transactions and privately earn yield on Aave.
"On Ethereum, everything you do is public. That's why we built Nyx: a private account governed by your Ethereum wallet", said Nikhil, Co-founder of Nyx. "Now you can send, receive and earn in private. Nyx was the first app live on the Aztec Alpha, and we're excited to expand participation to more users with the added stability of Alpha V5."
Other apps on Alpha V5 include Azguard and Nethermind (wallets), Shield, TRAIN, and RavenHouse (bridges), and the Aztecscan block explorers. Also launching is Dark Forest Aztec, a game where users explore a universe, control planets, manage planetary energy, expand territory, and launch attacks through strategic play with private state and hidden actions.

Transaction fees on Aztec come from two main sources: the cost of proving a transaction and the cost of verifying the rollup proof on Ethereum. Alpha V5 reduces both. It lowers the network's proving-cost parameter by 50%, and it reduces the L1 gas required to verify a rollup proof by approximately 40%. Because rollup proofs are verified on Ethereum and that cost is shared across all transactions in a batch, the L1 reduction lowers fees for every user, while the lower proving-cost parameter reduces the per-transaction proving fee directly. Together, these bring the average cost of a fully private token transfer to under a $0.05 transaction cost.
Alpha V5 also hardens the network on several fronts. It resolves critical vulnerabilities found in Alpha V4 along with additional bugs discovered since launch. Aztec's bug bounty program on Cantina also drew more than 234 security researchers to participate. The network remains in alpha, and further bugs may surface as usage grows, but each release has closed the issues found in the last and strengthened the protocol against new ones. With the critical V4 issues resolved and these safeguards in place, Alpha V5 is stable enough for teams to begin building and deploying applications.
Alpha V5 is live now, view the Alpha V5 landing page for a full list of features, performance updates, and live apps to explore.
Aztec is the only decentralized, privacy-first Layer 2 on Ethereum. Developers write private and public logic in the same smart contract, and private functions are executed and proven on the user's own device, so no operator sees the underlying data. The protocol is upgraded through onchain governance, and the network settles to Ethereum. For more information, visit aztec.network.
On Ethereum today, each transaction reveals everything publicly. The token you moved, the size, the timing, the wallet it came from, every action you take. Given the limitations of this type of transparent network, the industry is now focusing on bringing privacy onchain as a top priority. The response to this has mostly been to enable private transactions that shield transfers in various ways. But when we look at how privacy works on Web2, it’s clear that users and developers need granular privacy controls: the ability to decide what is public or private and who is able to see different types of data.
Aztec was built so that one transaction can carry two halves. A private half that runs on your own device and never leaves it, and a public half that the network runs in the open. Apps can choose which aspects are private or public, and users can choose what they want to reveal and when.
This article will follow an example transaction on Aztec: a vote in an onchain election built on Aztec, where who you are and which candidate you chose stay private, while the running tally for each candidate stays public for anyone to verify.
Picture the vote you cast in our example as two aspects that seamlessly weave together. In the first step, you act in private: an app records your vote on your device and hands the network a proof that the vote is valid without revealing it. In the second, the network acts in public: it checks that proof, then adds one to the chosen candidate's public tally. It is one transaction: one part stays with you, one part goes to the network. Both parts end up recorded onchain, in two separate state trees, one private and one public. The walkthrough below follows how these two aspects work together and what this means for how your transaction lands onchain.
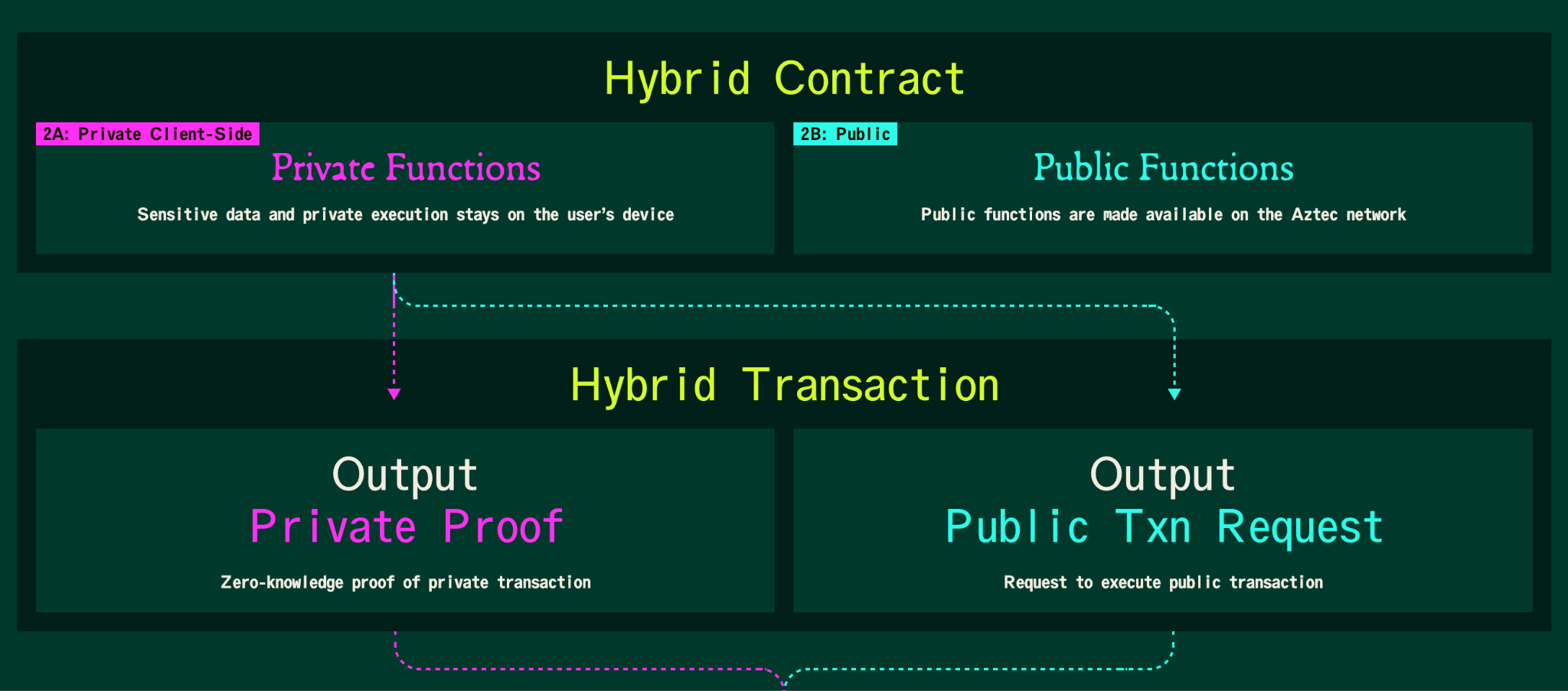
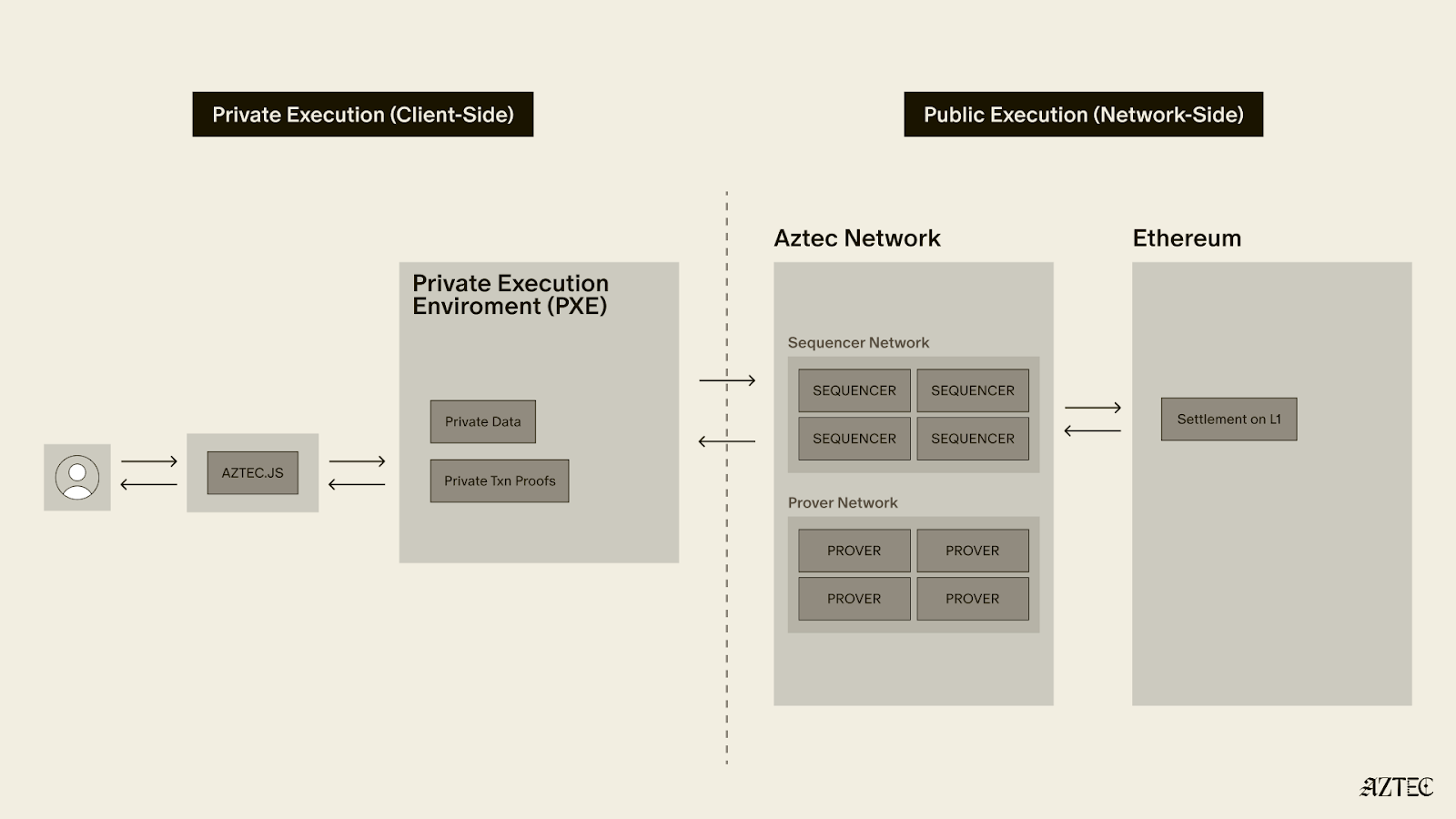
You open the voting app and connect an Aztec wallet. That first step looks like any onchain app. The difference is inside the wallet. An Aztec wallet carries a private execution environment, the PXE, pronounced "pixie", which runs on your phone or in your browser. The PXE is where the private half of your transaction executes, and where the proof of that work gets made, on your hardware, under your exclusive control.
Every account on Aztec is a smart contract rather than a bare key. That design, account abstraction, allows a wallet to authorize a transaction however its owner chooses without writing an identity onto the network for everyone to read. The wallet is the front door, and on Aztec you can decide if the door is open or closed, who you share your information with.
The voting app is a smart contract with two kinds of functions. The private functions run first, and they run inside your PXE. Your identity and the candidate you picked are the private inputs, and they stay on your device.
The only thing to leave your device is a proof confirming the legitimacy of your vote. Aztec's client-side proving system, Chonk, takes the private execution and produces a zero-knowledge proof: a compact cryptographic receipt that your vote followed the rules, that you are eligible, and have not voted before, while revealing nothing about who you are or who you voted for. Think of it as a sealed ballot the network can confirm is valid without opening it. The network learns only that a legitimate vote happened. It does not learn how you voted, or even which account voted.
This is the part that used to be too slow to be practical. Generating a proof on a phone was the bottleneck every privacy app hit. Aztec’s Chonk is purpose-built for fast proving on low-memory devices, both natively and in the browser, so the private half runs on the device in your hand instead of on someone else's server.
Some elements of a vote should be public. The tally is shared infrastructure, the number everyone relies on to trust the result. Thanks to programmable privacy on Aztec, the app marks that part public. Public functions live on the network and run in the open, the way functions do on Ethereum.
On Aztec, private and public logic live in the same contract, and the developer decides which is which, function by function and variable by variable. Programmable privacy is a dimmer, not a switch. The voting app turns it up on the individual ballot and turns it down on the running tally. That boundary is a design decision written into the contract, and it is the thing no transparent chain and no fixed-privacy chain can offer.
Your vote leaves your device as a bundle: the zero-knowledge proof of the private half, plus the call to the public function that updates the count. It goes to Aztec's sequencers, a decentralized set of thousands of independent operators, with more than 3,500 of them running the network today.
The sequencers do two jobs at once. They verify the proof of your private vote, confirming it is valid and eligible without seeing the choice behind it, and they run the public function that adds one to the chosen candidate and updates the public tally. Your ballot stays sealed. The count goes up by one for everyone to see. The same proof guarantees you cannot vote twice, even though no one learns which ballot is yours.

Aztec has two main state trees, and both live onchain. One holds private state, the other holds public state, so the full record of what happened sits on the network rather than on any one person's laptop. The two trees store each record in two different ways depending on if it needs to be private or public.
The private tree uses a UTXO model, the same note-based design used by Zcash. In this model, state is written as commitments: each entry is a sealed record that a valid vote was cast, with the voter and the choice kept private. Just like with Zcash or Bitcoin, you do not edit a private entry in place. You write a new one, and the design stops the same vote from being cast twice (old state is nullified). The vote stays private, and the record of a legitimate vote happening is onchain for the network to check.
The public tree uses an account-based model, the same shape Ethereum uses: values that update in place, readable by anyone. This is where each candidate's tally lives.
One transaction wrote information to both trees. The private tree recorded that you voted, sealed. The public tree recorded the new totals, in the open. Everything is onchain. The difference between the two trees is how much each one reveals.
Every private app on Aztec writes into that same private tree. A vote, a payment, and a payroll run all land in one shared record of activity, so each user's privacy grows stronger as the network grows, instead of splitting into a separate pool for every app.
Aztec is an L2 on Ethereum, so everything settles to Ethereum L1. A sequencer on Aztec gathers transactions into a proposed block. Other sequencers validate it before it goes to Ethereum's pending chain. At that point the block sits on Ethereum, ordered and recorded, waiting for its proof. The network has agreed on what happened and the proposed block is just waiting a final proof.
Proving a block is its own job, and on Aztec, it belongs to no one in particular. A decentralized, permissionless set of provers competes to take a full epoch, a 32-block stretch of the chain, and compresses it into a single zero-knowledge proof of the entire epoch. Anyone with the hardware can run a prover and bid for the work. There is no privileged operator, no committee you have to trust, no outside network holding a key.
That openness is the whole point of a privacy layer. A system that protects your data but routes it through one trusted server has only moved the exposure rather than removed it. Aztec keeps proving permissionless and your private inputs on your device, thereby avoiding any exposure.
The economics land in the voter's favor too. As an L2 network, Aztec spreads the cost of that one L1 proof across thousands of transactions in the rollup, so a vote costs pennies, not the millions of gas a private proof would cost verified alone on Ethereum.

A prover then posts the epoch proof to Ethereum's proven chain, and the Aztec state is final. Ethereum verifies one proof and inherits the correctness of everything inside it. Aztec extends Ethereum and settles to Ethereum, so your hybrid transaction carries Ethereum's security without carrying Ethereum's enforced transparency.
Anyone can now verify that the result is valid and that every counted vote was legitimate. No one can see how any individual voted. The tally is on the shared ledger where it belongs, and your ballot stayed yours the whole way through.
For the voter, their ballot was never a broadcast. The candidate you chose stayed yours, with no record tying your wallet to a name for anyone to read later, and you can still check that your vote was counted and the result is honest. You took part without your choice becoming data for systems built to act on it.
For a founder, the election app in this walkthrough is easy to implement without needing to build extensive custom code. Secret ballots with a public, verifiable count, in one contract, is a product category that opens up only because the boundary is programmable. You can build governance, elections, and polls where people vote without fear and the result still proves itself. And of course you can build anything that requires both public and private state to work seamlessly together.
For an infrastructure provider, the same machinery serves clients who need a result they can stand behind without exposing the people who produced it. Selective disclosure lets a client prove exactly what a counterparty needs to see, the count and the integrity of the process, and protect everything else, on their own terms. That is a guarantee a transparent chain cannot make.
A real vote needs two things at once: a secret ballot and a count anyone can check. A transparent chain makes you give up the first to get the second. On Aztec, you get both. The tally settled on Ethereum for anyone to verify, and how you voted stayed yours. The infrastructure is in place, what will you create with it?
Crypto is in a long night. It is no secret that the industry is facing challenging circumstances and there has been a clear consolidation of the industry. Right now we are seeing a focus on real traction, demonstrable value projects shipping practical solutions that will meaningfully reach users.
Some of that discipline is overdue. However, in times like these the properties that made crypto structurally different begin to look expendable. Decentralization slows you down. It makes upgrades harder. It makes institutional sales harder. It removes the control surfaces that the existing financial world knows how to buy.
We used to accept those costs as the price of building something durable. But, in a famine, they look like unaffordable affectations. Discarding them wholesale, however, is like selling the land out from under our feet.
Permissionless, uncensorable transaction networks with rich composability - this is the clay from which our industry was grown. The long term commercial health of our industry depends on preserving these properties in an age of privacy and institutional adoption.
These trade-offs become more challenging and pernicious when privacy is involved. Privacy is the narrative for crypto in 2026, and for good reason. It’s the missing piece that will deliver the traction and real use-cases that the industry so desperately needs.
The challenges of decentralization multiply under the constraints of privacy and what we are seeing in the industry is not a pivot, but a complete capitulation of all of the differentiable value that made crypto valuable.
I have spent nearly a decade building a network that marries programmable privacy with decentralization. A network where users keep their data, where applications are composable with one another, where transactions can settle without a privileged party learning everyone’s business or deciding which products are allowed to exist. That required new cryptography, new programming models, new state architecture, new wallets, and a fairly insane number of tradeoffs that are invisible until you try to build the thing yourself. There are easier products to ship.
A centralized privacy service can give institutions something legible quickly, replicating how the existing financial sector works: a responsible operator, a viewing key, a way to block transactions, a way to explain the whole thing to a risk committee. Some of these products will be useful. Some will be good businesses. But they are not the thing we came here to build.
Institutional and enterprise adoption is one of the core growth areas in this crypto-winter and the playbook is simple: use the language of crypto as a skin-suit to sell products and services that pattern match onto existing financial rails, with their need for complete visibility, censorship, centralized network operators and all of the liabilities this incurs.
This is a tempting bargain because it shortens the path to adoption. It gives buyers and regulators a shape they understand. A company. A contract. A switch. But the moment you accept that bargain, the system changes character. It may still be encrypted. It may still contain proofs. It may still call itself private. But, it now behaves like and is an operated service.
There is a party with privileged knowledge and privileged control. Builders must shape themselves around it. Institutions negotiate with it. Regulators may pressure it. Attackers target it. Users ultimately depend on it. By a backdoor I mean something specific: a network or protocol-level viewing key where the product developer does not control who can see their users’ data, especially when paired with network-level controls that can block transactions or ban smart contracts entirely. I do not mean application-level controls. I do not mean user-authorised disclosure. I do not mean a dapp deciding that users must prove something before using it. Regulated applications will need rules. The issue is that the disclosure boundary of your application belongs to somebody else, and the same layer that sees can also decide whether your users are allowed to transact. In short, users lack a platform that has credible neutrality.
Privacy on top of centralized rails is fatal. If one party can see everything and stop anything, that party may be treated as responsible for seeing and stopping.
This compounds into substantial platform risk. If an entity builds on top of such a system they must surrender visibility and control to the network operator to satisfy their liabilities without consideration for yours. Decentralization and ultimately credible neutrality is the difference between whether you own durable infrastructure or are renting a service whose rules can change on a whim. Worse, you cannot “just build things”. For novel transaction flows approval must be sought and granted. Tell me, would Ethereum have grown if every smart contract deployment required approval from the Ethereum Foundation?
Privacy needs the same freedom. A private credit market, for example, touches identity, collateral, repayment history, payment flows, liquidation logic, lender disclosures, auditor access and borrower privacy. If every component lives inside a different permissioned service, each with its own operator and viewing assumptions, that is a bureaucratic friction that negates blockchain’s core value proposition; composability.
A decentralized and credibly neutral privacy network prevents the settlement layer from becoming the single place where all surveillance and censorship obligations naturally accumulate. It allows product developers to scope their code to satisfy their own narrow requirements without consideration for the obligations of a centralized operator.
A lot of today’s privacy narrative treats architecture as if it were a detail. It is not. You cannot take a transparent ledger, staple confidentiality onto the edge, add a viewing key for comfort, and expect to get programmable private infrastructure.
If the state model is not private from the ground up you get wrappers, third party tools, data custodians, ad hoc disclosure paths and a pile of assumptions that every application drags into the next. Developers do not get a normal programming model where private contracts can call private contracts and users keep state on their own devices. They do not get composability.
The difference matters. In a real private execution environment, users generate transactions locally. They do not outsource their intent to a third party who learns what they are doing. Private contracts interact through a state model designed for privacy. The network settles proofs without becoming the party that knows everyone’s business. Privacy is part of the architecture.
This is why Aztec has taken so long. We built something that makes programmable private state and decentralised settlement live inside the same system. That means proving systems that run on consumer hardware, a transaction architecture built around local private execution, and a programming model where privacy is idiomatic and just works out of the box.
A centralized service can skip much of this. It can hold the key, run the prover, approve the flow and call the result privacy. It gets to market faster because it is not trying to arrive at the same place.
Adding decentralization does not make obligations disappear. Applications, issuers, frontends, custodians and regulated businesses will continue to exist in a web of obligations and responsibilities. Anyone pretending otherwise is unserious.
The question is where those obligations live. If they are pushed into the settlement layer, the settlement layer is no longer credibly neutral. It needs visibility into everyone and controls over everyone.
The better answer is selective disclosure. Users and applications should prove specific facts to specific parties for specific purposes. A regulated application may need to know that a user passed a check, that a transaction satisfies a policy, or that an auditor can inspect a particular flow. None of that requires the base network to hold a permanent key into everyone’s activity.
This will be harder to explain to the existing world. New infrastructure always fails to fit the categories built for the old infrastructure. Bitcoin did not arrive as a neatly regulated bank product. Ethereum did not wait for every lawyer to understand smart contracts. Stablecoins and DeFi forced institutions, regulators and users to develop new language around rails that kept existing.
If the standard for privacy infrastructure is to plug into the old world without changing anything, the answer will always be a service with a backdoor. And the result will be to catch crumbs falling from the tables of the old world.
The market we should be building is, well, a market. A private financial system that compounds: assets, liquidity, identity, credentials, credit and applications interacting through a shared settlement layer without forcing users to surrender their data to whoever sits in the middle.
Traditional finance is built out of vertically integrated information silos. Those silos are its moat. Banks, exchanges, custodians, payment processors and data brokers all benefit from controlling the information that flows through them. A global private settlement layer attacks that advantage directly. It lets liquidity and credentials move while outsourcing information custody to neutral cryptographic infrastructure.
A company wants a moat. A settlement layer wants surface area. A permissioned privacy provider can ration access, raise fees, exclude applications, shape disclosure rules and define acceptable use around its own risk tolerance. These are products pretending to be networks, and not durable financial infrastructure. What bothers me is this compounding category confusion. Networks adding protocol-level viewing keys and transaction controls are using the same language as decentralised programmable privacy, and commentators are treating them as variations of the same thing. They are not.
We have spent nine years walking the hard road. Now, just as we are close, the market has lost faith. Everyone is reaching for whatever lifeline looks immediate. Some of those lifelines will be real. Some will make money. But if crypto responds to its long night by rebuilding financial privacy as permissioned services, then we will have survived by surrendering the property that made the industry worth building.
Markets can grow when the platform is removed from the position where it can dictate the rules. It would be perverse to forget that lesson while building privacy, the domain where control over information matters most.
Crypto is in a famine. The land is struggling. We could sell our land for a pittance and survive the season. But the famine will pass, and when it does the land will blossom again. Without the land we are nothing.
We have struggled immensely to create a permissionless network that can marry privacy with decentralisation: an indestructible network whose users cannot be surveilled and whose transactions cannot be censored. This is the soil we have to grow our crops. To surrender a backdoor or a centralized operator for temporary relief is to sell our land for the price of a stablecoin. And we cannot sell the land.
Follow Zac on X to get more insights
Follow Aztec on X for updates & breaking news
Privacy has become a baseline requirement for L1s and L2s who care about bringing real-world users onchain. Users don't want their activity broadcast to competitors or the general public, but applications operating at scale also need some form of auditability, whether for regulators, compliance requirements, or tax reporting. Selective disclosure resolves that tension: privacy by default, with the ability to prove specific facts when required. What separates these networks is not whether they offer that switch, but who gets to hold it.
Aztec, Canton, Starknet, Tempo, and zkSync all offer some form of privacy with selective disclosure, but under the hood they make fundamentally different architectural decisions about who can see your data and who can turn your privacy off. Those decisions determine whether your privacy stays under your own control or sits behind a switch that someone else operates.
Three questions reveal where these networks actually diverge:
The answers determine whether your privacy off-switch is held by a policy, by an operator's good behavior, or by you alone through a cryptographic proof. As you'll see in this post, there are legitimate reasons to use each one with different tradeoffs. Aztec is the only network, however, where that switch stays in the user's hands, answering all three questions without putting a permissioned set of operators or a standing viewing key in control of your privacy. That gives developers the flexibility to build apps that comply with applicable laws while still keeping full privacy under the user's control.
This article will compare the privacy approaches of Aztec, Canton, Starknet, Tempo, and zkSync to give developers insight into the privacy tradeoffs of each network.
Here’s how each network handles the selective disclosure privacy off-switch, and who has control over your privacy:
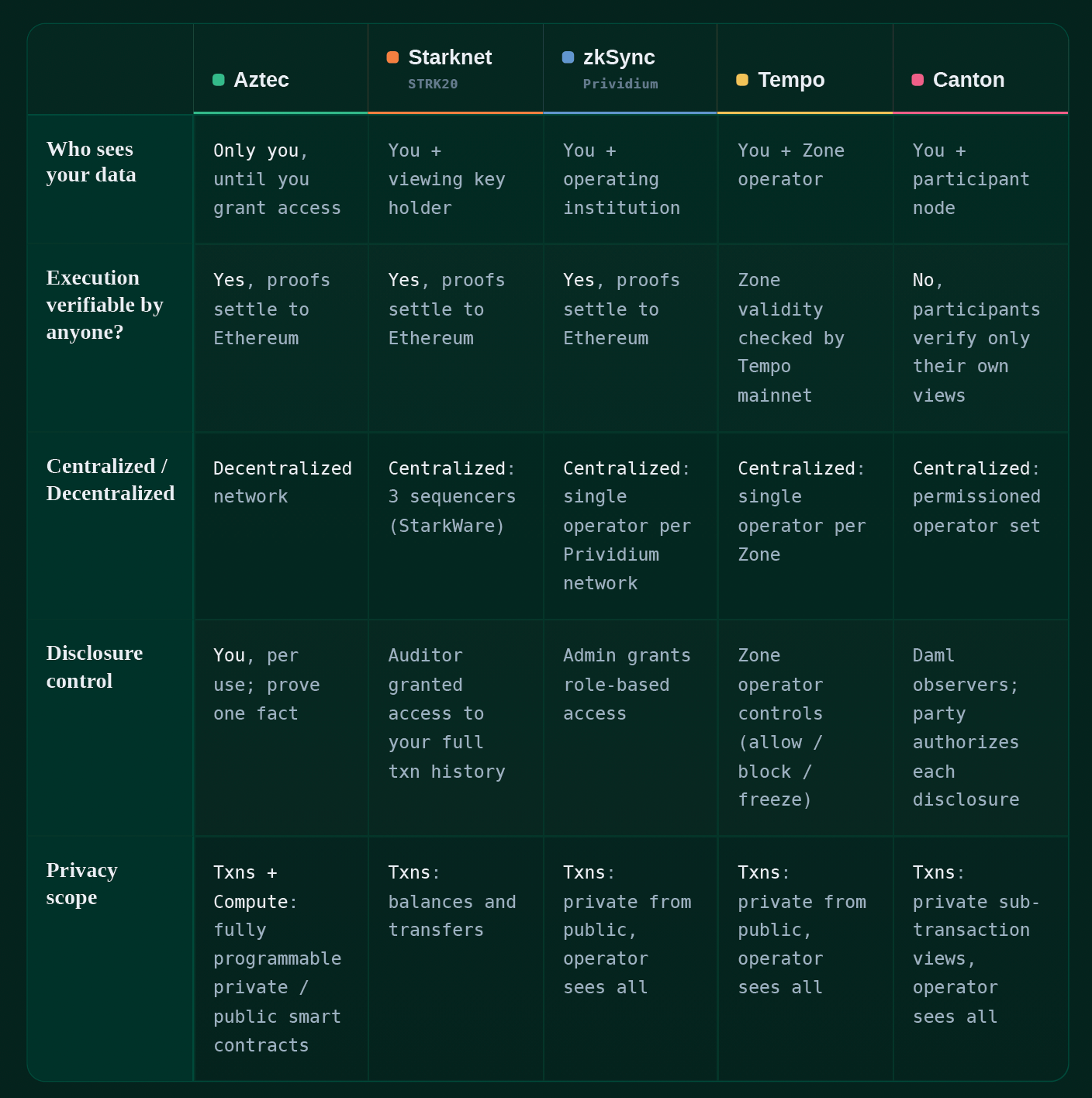
Each of these networks offers privacy with selective disclosure, but each rests on a different network design with its own tradeoffs. We have ordered them by who holds your privacy off-switch, starting with designs where a third party controls access to your data and ending with designs where that control stays with you. At the top, the switch sits behind a policy promise and an honest operator, and further down it is replaced by proofs that the user generates and controls.
Canton keeps data private by controlling viewing permissions for the various actors on its network. A transaction splits into per-participant views, so each party receives only the sub-transactions that name it, and the parts it is not entitled to never reach it. The sequencer and mediator move those views without reading them, which is real privacy against those roles.
However, the data is still read in plaintext by the participant nodes that host the relevant parties, and in the common regulated-asset pattern where the issuer is a signatory on its own token, the issuer's node sees every transfer. The harder gap is verification, because no third party can reconstruct the global ledger, so correctness rests on the confirming nodes staying honest and their keys staying safe. In practice the off-switch sits with those nodes rather than with you, since you cannot see when your data is read and cannot stop it.
Tempo is designed for payments and uses validity proofs to verify that each zone is executing correctly, while still giving the zone operator full plaintext visibility into every transaction within that zone. Privacy comes from Tempo Zones, which are parallel execution environments connected to the Tempo mainnet.
By design, the zone operator has visibility into all transactions within the zone, while users see only their own and the public sees only a proof that the zone is valid. Token issuers set compliance controls, allowlists, blocklists, and freezes, enforced across zones. The mainnet checks each zone's validity, so execution is verified, while the operator still reads every transaction in plaintext and holds the off-switch over what is revealed. Your privacy is from the public, not from the operator.
zkSync Prividium adds the verifiability piece that Canton lacks. Every batch produces a validity proof settled to Ethereum, so a compromised operator cannot forge state or mint tokens from nothing without also forging a proof, which it cannot do. The tradeoff is that the operator processes every transaction in plaintext and decides who sees what, which means the off-switch stays with the operator and your privacy is from the outside world rather than from the operator itself.
This tradeoff has legitimate uses in high-trust institutional environments. If Bank of America, JPMorgan, and Wells Fargo are transacting on a shared network, a zone where BofA's infrastructure processes BofA-originated transactions satisfies internal control requirements while still delivering genuine ZK privacy from the other banks and the rest of the world. Where this model breaks down is in lower-trust environments where giving an operator full plaintext access and the switch that comes with it holds back product design possibilities.
Starknet's STRK20 breaks from relying on an operator for privacy. It shields ERC-20 balances and transfers in a privacy pool, and every private transaction carries a zero-knowledge proof generated client-side, so no operator sees your plaintext in order to build it.
Disclosure is where STRK20 diverges from Aztec. To join the Starknet Privacy Pool, you register an encrypted viewing key onchain, and it sits there for the life of your participation. On a regulatory request, a designated auditing entity can decrypt that key and trace your complete transaction history, forwards and backwards. StarkWare calls this ‘not a backdoor’ but a carefully scoped access mechanism, and the safeguard is a policy promise that the auditor decrypts only when required. The privacy is cryptographic, but the off-switch is a standing key that someone else holds and can flip whether or not you are watching.
On Aztec your private state lives as encrypted private data that only you can decrypt. The contract developer can choose what state is public and what is private, and whether your encrypted private data is emitted onchain as a private log or shared off-chain instead.
Your transactions get proven client-side on your own device, so no sequencer or operator sees your unencrypted private data. Those proofs settle to Ethereum, which gives the same integrity anchor marketed by Prividium, with every transaction verified and no forged state, but without a single operator who reads your data. The base protocol decentralizes sequencing, proving, and governance, so there is no operator to choose and trust in the first place.
Disclosure is your choice too: you decide who learns your private data, and whether they learn it in encrypted or decrypted form. To grant discovery without readability, you share an app-specific tagging secret that lets an auditor find your data in encrypted form without being able to decrypt and read it. This is enough to prove things calculated from that data, such as a tax basis or a profit and loss figure. Granting permission to actually read the data works differently. There's no per-contract read key you can hand out, because decryption uses your master viewing key, which would unlock all your data across every contract. So instead of sharing a key, you share the data itself, plus a proof that your plaintext is what encrypts to the on-chain ciphertext.
Aztec has true selective disclosure in that you can selectively share it, and nothing else you don’t need to. This is app specific, meaning that private data discoverability access on one app does not grant access on another. Most importantly, the off-switch stays in your hands, and you never need to trust the network to handle access to any of your private data and activity.
This is not just conceptual: here is a working proof-of-concept of this model on Aztec. PrivPNL takes you from private DEX trades through a tagging-key disclosure to a browser-generated ZK proof of your PnL. The auditor verifies a proof while the prover only has to reveal the amount they owe, and your portfolio stays private.
Canton keeps the switch with the participant nodes that read your data in plaintext, so disclosure rests on those nodes staying honest rather than on anything you control. Tempo similarly gives the off-switch to a zone-based node operator, but allows you to verify the correctness of transactions using validity proofs. Prividium hardens that promise with a proof settled to Ethereum, a real improvement, but the operator still reads every transaction and still decides who sees what. This can work well for large institutions, but small to medium sized enterprises are left with the same privacy as their current banks unless they run their own Prividium nodes. STRK20 moves the switch into a standing viewing key and asks you to trust that a designated auditor reaches for it only when needed. In each of these models the real question is not whether your privacy can be switched off, but who gets to do the switching, and whether you would even know it happened.
Aztec takes the operator and the standing key out of the question entirely. You keep the data, you generate the proof, and you disclose the result, one fact at a time and only when you choose to. The off-switch never leaves your hands, and no operator, auditor, or node can reach it on your behalf. This is one of the benefits of a network that offers fully programmable, privacy-preserving smart contracts that put you in control.
Selective disclosure is how privacy survives contact with a regulator, and the model you pick decides who can open your history when you are not looking. On Aztec, that answer is no one but you.
Dive into the technical details: Try a live demo of selective disclosure on Aztec and read the technical article on how it was built.
Integrate with Aztec: Reach out if you are interested in integrating privacy into your project.
The Aztec Network today activated Alpha V5, a major protocol upgrade passed by token-holder governance and executed onchain. Alpha V5 reduces private-transaction proving times by more than 2x compared to the previous version, lowers the cost of a fully private transaction by roughly 50%, resolves the critical issues found in V4, and sees the first wave of apps go live. Users can now send private transactions and earn yield on Aave simply by connecting their Ethereum wallets on Nyx, bridge from Ethereum to Aztec using Shield or TRAIN, privately collect NFTs on RavenHouse, or play Dark Forest Aztec, a hidden-information strategy game in a universe that lives entirely onchain.
"Alpha V5 continues Aztec's work at the frontier of client-side proving, with cryptographic breakthroughs that cut proving times by more than half this release," said Zac Williamson, Co-founder, Aztec Foundation. "We believe Aztec is now the fastest system in the world for proving a fully private transaction entirely on a user's own device, and every release moves the industry closer to private transactions at public transaction speeds."
As the only decentralized privacy L2, Aztec is the credibly neutral privacy layer for Ethereum. Aztec allows anyone to write smart contracts that include both private and public aspects – every private transaction is proven on the user's own device, so no operator, sequencer, or intermediary can see the data. The Alpha V5 proving improvements come from cryptographic advances that make this client-side proving faster than any prior release. The network remains in alpha, but with V5 it is ready for teams to begin building and deploying applications.
Making private transactions practical comes down to how quickly a proof can be generated on a user's own device, without offloading that work to a server that would learn what the user is doing. On Alpha V5, proving a private token transfer natively now takes approximately 2.5 seconds on a consumer laptop, down from 5.2 seconds on V4, and about 6.8 seconds in a browser, down from 12.5 seconds. Across every measured transaction flow, client-side proving times improved by approximately 2x compared with V4.
Alpha V5 lowers ECDSA signature-verification cost by approximately 2x, speeds up Poseidon2 hashing by approximately 3x, and reduces the protocol circuit gate count by approximately 50% (gate count is the number of individual operations a proving circuit must perform, and it is the main driver of how long a proof takes to generate). Each of these lowers the amount of work a device performs to prove a transaction, and the reduction in gate count in particular compounds across every proof the network generates.
Alpha V5 launches the first wave of apps on a network where privacy is built into the protocol rather than managed by an operator. On other networks that claim privacy, transactions still pass through an operator or node that reads them in plaintext, or depend on a viewing key that a third party holds, so users rely on someone else to protect their data and to decide when it gets disclosed. On Aztec, every private transaction is proven on the user's own device, so the app, the sequencer, and any operator never need to see the underlying data. Nyx is one of these apps, allowing users to privately send transactions and privately earn yield on Aave.
"On Ethereum, everything you do is public. That's why we built Nyx: a private account governed by your Ethereum wallet", said Nikhil, Co-founder of Nyx. "Now you can send, receive and earn in private. Nyx was the first app live on the Aztec Alpha, and we're excited to expand participation to more users with the added stability of Alpha V5."
Other apps on Alpha V5 include Azguard and Nethermind (wallets), Shield, TRAIN, and RavenHouse (bridges), and the Aztecscan block explorers. Also launching is Dark Forest Aztec, a game where users explore a universe, control planets, manage planetary energy, expand territory, and launch attacks through strategic play with private state and hidden actions.
Transaction fees on Aztec come from two main sources: the cost of proving a transaction and the cost of verifying the rollup proof on Ethereum. Alpha V5 reduces both. It lowers the network's proving-cost parameter by 50%, and it reduces the L1 gas required to verify a rollup proof by approximately 40%. Because rollup proofs are verified on Ethereum and that cost is shared across all transactions in a batch, the L1 reduction lowers fees for every user, while the lower proving-cost parameter reduces the per-transaction proving fee directly. Together, these bring the average cost of a fully private token transfer to under a $0.05 transaction cost.
Alpha V5 also hardens the network on several fronts. It resolves critical vulnerabilities found in Alpha V4 along with additional bugs discovered since launch. Aztec's bug bounty program on Cantina also drew more than 234 security researchers to participate. The network remains in alpha, and further bugs may surface as usage grows, but each release has closed the issues found in the last and strengthened the protocol against new ones. With the critical V4 issues resolved and these safeguards in place, Alpha V5 is stable enough for teams to begin building and deploying applications.
Alpha V5 is live now, view the Alpha V5 landing page for a full list of features, performance updates, and live apps to explore.
Aztec is the only decentralized, privacy-first Layer 2 on Ethereum. Developers write private and public logic in the same smart contract, and private functions are executed and proven on the user's own device, so no operator sees the underlying data. The protocol is upgraded through onchain governance, and the network settles to Ethereum. For more information, visit aztec.network.
Crypto is in a long night. It is no secret that the industry is facing challenging circumstances and there has been a clear consolidation of the industry. Right now we are seeing a focus on real traction, demonstrable value projects shipping practical solutions that will meaningfully reach users.
Some of that discipline is overdue. However, in times like these the properties that made crypto structurally different begin to look expendable. Decentralization slows you down. It makes upgrades harder. It makes institutional sales harder. It removes the control surfaces that the existing financial world knows how to buy.
We used to accept those costs as the price of building something durable. But, in a famine, they look like unaffordable affectations. Discarding them wholesale, however, is like selling the land out from under our feet.
Permissionless, uncensorable transaction networks with rich composability - this is the clay from which our industry was grown. The long term commercial health of our industry depends on preserving these properties in an age of privacy and institutional adoption.
These trade-offs become more challenging and pernicious when privacy is involved. Privacy is the narrative for crypto in 2026, and for good reason. It’s the missing piece that will deliver the traction and real use-cases that the industry so desperately needs.
The challenges of decentralization multiply under the constraints of privacy and what we are seeing in the industry is not a pivot, but a complete capitulation of all of the differentiable value that made crypto valuable.
I have spent nearly a decade building a network that marries programmable privacy with decentralization. A network where users keep their data, where applications are composable with one another, where transactions can settle without a privileged party learning everyone’s business or deciding which products are allowed to exist. That required new cryptography, new programming models, new state architecture, new wallets, and a fairly insane number of tradeoffs that are invisible until you try to build the thing yourself. There are easier products to ship.
A centralized privacy service can give institutions something legible quickly, replicating how the existing financial sector works: a responsible operator, a viewing key, a way to block transactions, a way to explain the whole thing to a risk committee. Some of these products will be useful. Some will be good businesses. But they are not the thing we came here to build.
Institutional and enterprise adoption is one of the core growth areas in this crypto-winter and the playbook is simple: use the language of crypto as a skin-suit to sell products and services that pattern match onto existing financial rails, with their need for complete visibility, censorship, centralized network operators and all of the liabilities this incurs.
This is a tempting bargain because it shortens the path to adoption. It gives buyers and regulators a shape they understand. A company. A contract. A switch. But the moment you accept that bargain, the system changes character. It may still be encrypted. It may still contain proofs. It may still call itself private. But, it now behaves like and is an operated service.
There is a party with privileged knowledge and privileged control. Builders must shape themselves around it. Institutions negotiate with it. Regulators may pressure it. Attackers target it. Users ultimately depend on it. By a backdoor I mean something specific: a network or protocol-level viewing key where the product developer does not control who can see their users’ data, especially when paired with network-level controls that can block transactions or ban smart contracts entirely. I do not mean application-level controls. I do not mean user-authorised disclosure. I do not mean a dapp deciding that users must prove something before using it. Regulated applications will need rules. The issue is that the disclosure boundary of your application belongs to somebody else, and the same layer that sees can also decide whether your users are allowed to transact. In short, users lack a platform that has credible neutrality.
Privacy on top of centralized rails is fatal. If one party can see everything and stop anything, that party may be treated as responsible for seeing and stopping.
This compounds into substantial platform risk. If an entity builds on top of such a system they must surrender visibility and control to the network operator to satisfy their liabilities without consideration for yours. Decentralization and ultimately credible neutrality is the difference between whether you own durable infrastructure or are renting a service whose rules can change on a whim. Worse, you cannot “just build things”. For novel transaction flows approval must be sought and granted. Tell me, would Ethereum have grown if every smart contract deployment required approval from the Ethereum Foundation?
Privacy needs the same freedom. A private credit market, for example, touches identity, collateral, repayment history, payment flows, liquidation logic, lender disclosures, auditor access and borrower privacy. If every component lives inside a different permissioned service, each with its own operator and viewing assumptions, that is a bureaucratic friction that negates blockchain’s core value proposition; composability.
A decentralized and credibly neutral privacy network prevents the settlement layer from becoming the single place where all surveillance and censorship obligations naturally accumulate. It allows product developers to scope their code to satisfy their own narrow requirements without consideration for the obligations of a centralized operator.
A lot of today’s privacy narrative treats architecture as if it were a detail. It is not. You cannot take a transparent ledger, staple confidentiality onto the edge, add a viewing key for comfort, and expect to get programmable private infrastructure.
If the state model is not private from the ground up you get wrappers, third party tools, data custodians, ad hoc disclosure paths and a pile of assumptions that every application drags into the next. Developers do not get a normal programming model where private contracts can call private contracts and users keep state on their own devices. They do not get composability.
The difference matters. In a real private execution environment, users generate transactions locally. They do not outsource their intent to a third party who learns what they are doing. Private contracts interact through a state model designed for privacy. The network settles proofs without becoming the party that knows everyone’s business. Privacy is part of the architecture.
This is why Aztec has taken so long. We built something that makes programmable private state and decentralised settlement live inside the same system. That means proving systems that run on consumer hardware, a transaction architecture built around local private execution, and a programming model where privacy is idiomatic and just works out of the box.
A centralized service can skip much of this. It can hold the key, run the prover, approve the flow and call the result privacy. It gets to market faster because it is not trying to arrive at the same place.
Adding decentralization does not make obligations disappear. Applications, issuers, frontends, custodians and regulated businesses will continue to exist in a web of obligations and responsibilities. Anyone pretending otherwise is unserious.
The question is where those obligations live. If they are pushed into the settlement layer, the settlement layer is no longer credibly neutral. It needs visibility into everyone and controls over everyone.
The better answer is selective disclosure. Users and applications should prove specific facts to specific parties for specific purposes. A regulated application may need to know that a user passed a check, that a transaction satisfies a policy, or that an auditor can inspect a particular flow. None of that requires the base network to hold a permanent key into everyone’s activity.
This will be harder to explain to the existing world. New infrastructure always fails to fit the categories built for the old infrastructure. Bitcoin did not arrive as a neatly regulated bank product. Ethereum did not wait for every lawyer to understand smart contracts. Stablecoins and DeFi forced institutions, regulators and users to develop new language around rails that kept existing.
If the standard for privacy infrastructure is to plug into the old world without changing anything, the answer will always be a service with a backdoor. And the result will be to catch crumbs falling from the tables of the old world.
The market we should be building is, well, a market. A private financial system that compounds: assets, liquidity, identity, credentials, credit and applications interacting through a shared settlement layer without forcing users to surrender their data to whoever sits in the middle.
Traditional finance is built out of vertically integrated information silos. Those silos are its moat. Banks, exchanges, custodians, payment processors and data brokers all benefit from controlling the information that flows through them. A global private settlement layer attacks that advantage directly. It lets liquidity and credentials move while outsourcing information custody to neutral cryptographic infrastructure.
A company wants a moat. A settlement layer wants surface area. A permissioned privacy provider can ration access, raise fees, exclude applications, shape disclosure rules and define acceptable use around its own risk tolerance. These are products pretending to be networks, and not durable financial infrastructure. What bothers me is this compounding category confusion. Networks adding protocol-level viewing keys and transaction controls are using the same language as decentralised programmable privacy, and commentators are treating them as variations of the same thing. They are not.
We have spent nine years walking the hard road. Now, just as we are close, the market has lost faith. Everyone is reaching for whatever lifeline looks immediate. Some of those lifelines will be real. Some will make money. But if crypto responds to its long night by rebuilding financial privacy as permissioned services, then we will have survived by surrendering the property that made the industry worth building.
Markets can grow when the platform is removed from the position where it can dictate the rules. It would be perverse to forget that lesson while building privacy, the domain where control over information matters most.
Crypto is in a famine. The land is struggling. We could sell our land for a pittance and survive the season. But the famine will pass, and when it does the land will blossom again. Without the land we are nothing.
We have struggled immensely to create a permissionless network that can marry privacy with decentralisation: an indestructible network whose users cannot be surveilled and whose transactions cannot be censored. This is the soil we have to grow our crops. To surrender a backdoor or a centralized operator for temporary relief is to sell our land for the price of a stablecoin. And we cannot sell the land.
Follow Zac on X to get more insights
Follow Aztec on X for updates & breaking news
Privacy has become a baseline requirement for L1s and L2s who care about bringing real-world users onchain. Users don't want their activity broadcast to competitors or the general public, but applications operating at scale also need some form of auditability, whether for regulators, compliance requirements, or tax reporting. Selective disclosure resolves that tension: privacy by default, with the ability to prove specific facts when required. What separates these networks is not whether they offer that switch, but who gets to hold it.
Aztec, Canton, Starknet, Tempo, and zkSync all offer some form of privacy with selective disclosure, but under the hood they make fundamentally different architectural decisions about who can see your data and who can turn your privacy off. Those decisions determine whether your privacy stays under your own control or sits behind a switch that someone else operates.
Three questions reveal where these networks actually diverge:
The answers determine whether your privacy off-switch is held by a policy, by an operator's good behavior, or by you alone through a cryptographic proof. As you'll see in this post, there are legitimate reasons to use each one with different tradeoffs. Aztec is the only network, however, where that switch stays in the user's hands, answering all three questions without putting a permissioned set of operators or a standing viewing key in control of your privacy. That gives developers the flexibility to build apps that comply with applicable laws while still keeping full privacy under the user's control.
This article will compare the privacy approaches of Aztec, Canton, Starknet, Tempo, and zkSync to give developers insight into the privacy tradeoffs of each network.
Here’s how each network handles the selective disclosure privacy off-switch, and who has control over your privacy:
Each of these networks offers privacy with selective disclosure, but each rests on a different network design with its own tradeoffs. We have ordered them by who holds your privacy off-switch, starting with designs where a third party controls access to your data and ending with designs where that control stays with you. At the top, the switch sits behind a policy promise and an honest operator, and further down it is replaced by proofs that the user generates and controls.
Canton keeps data private by controlling viewing permissions for the various actors on its network. A transaction splits into per-participant views, so each party receives only the sub-transactions that name it, and the parts it is not entitled to never reach it. The sequencer and mediator move those views without reading them, which is real privacy against those roles.
However, the data is still read in plaintext by the participant nodes that host the relevant parties, and in the common regulated-asset pattern where the issuer is a signatory on its own token, the issuer's node sees every transfer. The harder gap is verification, because no third party can reconstruct the global ledger, so correctness rests on the confirming nodes staying honest and their keys staying safe. In practice the off-switch sits with those nodes rather than with you, since you cannot see when your data is read and cannot stop it.
Tempo is designed for payments and uses validity proofs to verify that each zone is executing correctly, while still giving the zone operator full plaintext visibility into every transaction within that zone. Privacy comes from Tempo Zones, which are parallel execution environments connected to the Tempo mainnet.
By design, the zone operator has visibility into all transactions within the zone, while users see only their own and the public sees only a proof that the zone is valid. Token issuers set compliance controls, allowlists, blocklists, and freezes, enforced across zones. The mainnet checks each zone's validity, so execution is verified, while the operator still reads every transaction in plaintext and holds the off-switch over what is revealed. Your privacy is from the public, not from the operator.
zkSync Prividium adds the verifiability piece that Canton lacks. Every batch produces a validity proof settled to Ethereum, so a compromised operator cannot forge state or mint tokens from nothing without also forging a proof, which it cannot do. The tradeoff is that the operator processes every transaction in plaintext and decides who sees what, which means the off-switch stays with the operator and your privacy is from the outside world rather than from the operator itself.
This tradeoff has legitimate uses in high-trust institutional environments. If Bank of America, JPMorgan, and Wells Fargo are transacting on a shared network, a zone where BofA's infrastructure processes BofA-originated transactions satisfies internal control requirements while still delivering genuine ZK privacy from the other banks and the rest of the world. Where this model breaks down is in lower-trust environments where giving an operator full plaintext access and the switch that comes with it holds back product design possibilities.
Starknet's STRK20 breaks from relying on an operator for privacy. It shields ERC-20 balances and transfers in a privacy pool, and every private transaction carries a zero-knowledge proof generated client-side, so no operator sees your plaintext in order to build it.
Disclosure is where STRK20 diverges from Aztec. To join the Starknet Privacy Pool, you register an encrypted viewing key onchain, and it sits there for the life of your participation. On a regulatory request, a designated auditing entity can decrypt that key and trace your complete transaction history, forwards and backwards. StarkWare calls this ‘not a backdoor’ but a carefully scoped access mechanism, and the safeguard is a policy promise that the auditor decrypts only when required. The privacy is cryptographic, but the off-switch is a standing key that someone else holds and can flip whether or not you are watching.
On Aztec your private state lives as encrypted private data that only you can decrypt. The contract developer can choose what state is public and what is private, and whether your encrypted private data is emitted onchain as a private log or shared off-chain instead.
Your transactions get proven client-side on your own device, so no sequencer or operator sees your unencrypted private data. Those proofs settle to Ethereum, which gives the same integrity anchor marketed by Prividium, with every transaction verified and no forged state, but without a single operator who reads your data. The base protocol decentralizes sequencing, proving, and governance, so there is no operator to choose and trust in the first place.
Disclosure is your choice too: you decide who learns your private data, and whether they learn it in encrypted or decrypted form. To grant discovery without readability, you share an app-specific tagging secret that lets an auditor find your data in encrypted form without being able to decrypt and read it. This is enough to prove things calculated from that data, such as a tax basis or a profit and loss figure. Granting permission to actually read the data works differently. There's no per-contract read key you can hand out, because decryption uses your master viewing key, which would unlock all your data across every contract. So instead of sharing a key, you share the data itself, plus a proof that your plaintext is what encrypts to the on-chain ciphertext.
Aztec has true selective disclosure in that you can selectively share it, and nothing else you don’t need to. This is app specific, meaning that private data discoverability access on one app does not grant access on another. Most importantly, the off-switch stays in your hands, and you never need to trust the network to handle access to any of your private data and activity.
This is not just conceptual: here is a working proof-of-concept of this model on Aztec. PrivPNL takes you from private DEX trades through a tagging-key disclosure to a browser-generated ZK proof of your PnL. The auditor verifies a proof while the prover only has to reveal the amount they owe, and your portfolio stays private.
Canton keeps the switch with the participant nodes that read your data in plaintext, so disclosure rests on those nodes staying honest rather than on anything you control. Tempo similarly gives the off-switch to a zone-based node operator, but allows you to verify the correctness of transactions using validity proofs. Prividium hardens that promise with a proof settled to Ethereum, a real improvement, but the operator still reads every transaction and still decides who sees what. This can work well for large institutions, but small to medium sized enterprises are left with the same privacy as their current banks unless they run their own Prividium nodes. STRK20 moves the switch into a standing viewing key and asks you to trust that a designated auditor reaches for it only when needed. In each of these models the real question is not whether your privacy can be switched off, but who gets to do the switching, and whether you would even know it happened.
Aztec takes the operator and the standing key out of the question entirely. You keep the data, you generate the proof, and you disclose the result, one fact at a time and only when you choose to. The off-switch never leaves your hands, and no operator, auditor, or node can reach it on your behalf. This is one of the benefits of a network that offers fully programmable, privacy-preserving smart contracts that put you in control.
Selective disclosure is how privacy survives contact with a regulator, and the model you pick decides who can open your history when you are not looking. On Aztec, that answer is no one but you.
Dive into the technical details: Try a live demo of selective disclosure on Aztec and read the technical article on how it was built.
Integrate with Aztec: Reach out if you are interested in integrating privacy into your project.
Alpha is live: a fully feature-complete, privacy-first network. The infrastructure is in place, privacy is native to the protocol, and developers can now build truly private applications.
Nine years ago, we set out to redesign blockchain for privacy. The goal: create a system institutions can adopt while giving users true control of their digital lives. Privacy band-aids are coming to Ethereum (someday), but it’s clear we need privacy now, and there’s an arms race underway to build it. Privacy is complex, it’s not a feature you can bolt-on as an afterthought. It demands a ground-up approach, deep tech stack integration, and complete decentralization.
In November 2025, the Aztec Ignition Chain went live as the first decentralized L2 on Ethereum, it’s the coordination layer that the execution layer sits on top of. The network is not operated by the Aztec Labs or the Aztec Foundation, it’s run by the community, making it the true backbone of Aztec.
With the infrastructure in place and a unanimous community vote, the network enters Alpha.
Alpha is the first Layer 2 with a full execution environment for private smart contracts. All accounts, transactions, and the execution itself can be completely private. Developers can now choose what they want public and what they want to keep private while building with the three privacy pillars we have in place across data, identity, and compute.

These privacy pillars, which can be used individually or combined, break down into three core layers:
Alpha is feature complete–meaning this is the only full-stack solution for adding privacy to your business or application. You build, and Aztec handles the cryptography under the hood.
It’s Composable. Private-preserving contracts are not isolated; they can talk to each other and seamlessly blend both private and public state across contracts. Privacy can be preserved across contract calls for full callstack privacy.
No backdoor access. Aztec is the only decentralized L2, and is launching as a fully decentralized rollup with a Layer 1 escape hatch.
It’s Compliant. Companies are missing out on the benefits of blockchains because transparent chains expose user data, while private networks protect it, but still offer fully customizable controls. Now they can build compliant apps that move value around the world instantly.

Developers can explore our privacy primitives across data, identity, and compute and start building with them using the documentation here. Note that this is an early version of the network with known vulnerabilities, see this post for details. While this is the first iteration of the network, there will be several upgrades that secure and harden the network on our path to Beta. If you’d like to learn more about how you can integrate privacy into your project, reach out here.
To hear directly from our Cofounders, join our live from Cannes Q&A on Tuesday, March 31st at 9:30 am ET. Follow us on X to get the latest updates from the Aztec Network.
Preventing sybil attacks and malicious actors is one of the fundamental challenges of Web3 – it’s why we have proof-of-work and proof-of-stake networks. But Sybil attacks go a step further for many projects, with bots and advanced AI agents flooding Discord servers, sending thousands of transactions that clog networks, and botting your Typeforms. Determining who is a real human online and on-chain is becoming increasingly difficult, and the consequences of this are making it difficult for projects to interact with real users.
When the Aztec Testnet launched last month, we wrote about the challenges of running a proof-of-stake testnet in an environment where bots are everywhere. The Aztec Testnet is a decentralized network, and in order to give good actors a chance, a daily quota was implemented to limit the number of new sequencers that could join the validator set per day to start proposing blocks. Using this system, good actors who were already in the set could vote to kick out bad actors, with a daily limit of 5 new sequencers able to join the set each day. However, the daily quota quickly got bottlenecked, and it became nearly impossible for real humans who are operating nodes in good faith to join the Aztec Testnet.
In this case study, we break down Sybil attacks, explore different ways the ecosystem currently uses to prevent them, and dive into how we’re leveraging ZKPassport to prevent Sybil attacks on the Aztec Testnet.
With the massive repercussions that stem from privacy leaks (see the recent Coinbase incident), any solution to prevent Sybil attacks and prove humanity must not compromise on user privacy and should be grounded in the principles of privacy by design and data minimization. Additionally, given that decentralization underpins the entire purpose of Web3 (and the Aztec Network), joining the network should remain permissionless.
Our goal was to find a solution that allows users to permissionlessly prove their humanity without compromising their privacy. If such a technology exists (spoiler alert: it does), we believe that this has the potential to solve one of the biggest problems faced by our industry: Sybil attacks. Some of the ways that projects currently try to prevent Sybil attacks or prove [humanity] include:
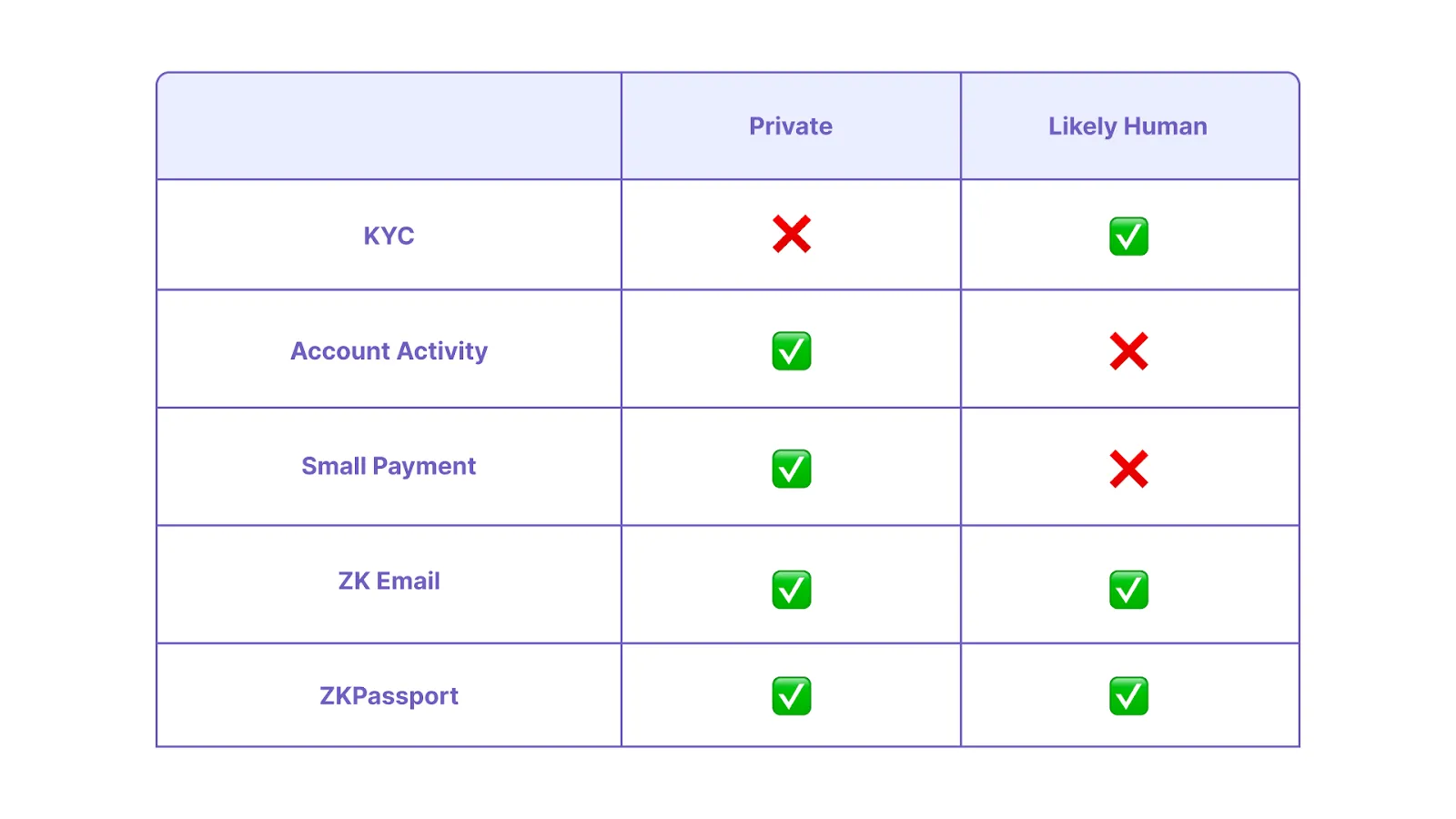
Both zkEmail and ZKPassport are powered by Noir, the universal language of zk, and are great solutions for preventing Sybil attacks.
With zkEmail, users can do things like prove that they received a confirmation email from a centralized exchange showing that they successfully passed KYC, all without showing any of the email contents or personal information. While this offers a good solution for this use case, we also wanted the functionality of enabling the network to block certain jurisdictions (if needed), without the network knowing where the user is from. This also enables users to directly interface with the network rather than through a third-party email confirmation.
Given this context, ZKPassport was, and is, the perfect fit.
For the Aztec Testnet, we’ve integrated ZKPassport to enable node operators to prove they are human and participate in the network. This integration allows the network to dramatically increase the number of sequencers that can be added each day, which is a huge step forward in decentralizing the network with real operators.
ZKPassport allows users to share only the details about themselves that they choose by scanning a passport or government ID. This is achieved using zero-knowledge proofs (ZKPs) that are generated locally on the user’s phone. Implementing client-side zk-proofs in this way enables novel use-cases like age verification, where someone can prove their age without actually sharing how old they are (see the recent report on How to Enable Age Verification on the Internet Today Using Zero-Knowledge Proofs).
As of this week, the ZKPassport app is live and available to download on Google Play and the Apple App Store.
Most countries today issue biometric passports or national IDs containing NFC chips (over 120 countries are currently supported by ZKPassport). These chips contain information on the full name, date of birth, nationality, and even digital photographs of the passport or ID holder. They can also contain biometric data such as fingerprints and iris scans.
By scanning the NFC chip located in their ID document with a smartphone, users generate proof based on a specific request from an app. For example, some apps might require only the user’s age or nationality. In the case of Aztec, no information is needed about the user other than that they do indeed hold a valid passport or ID.
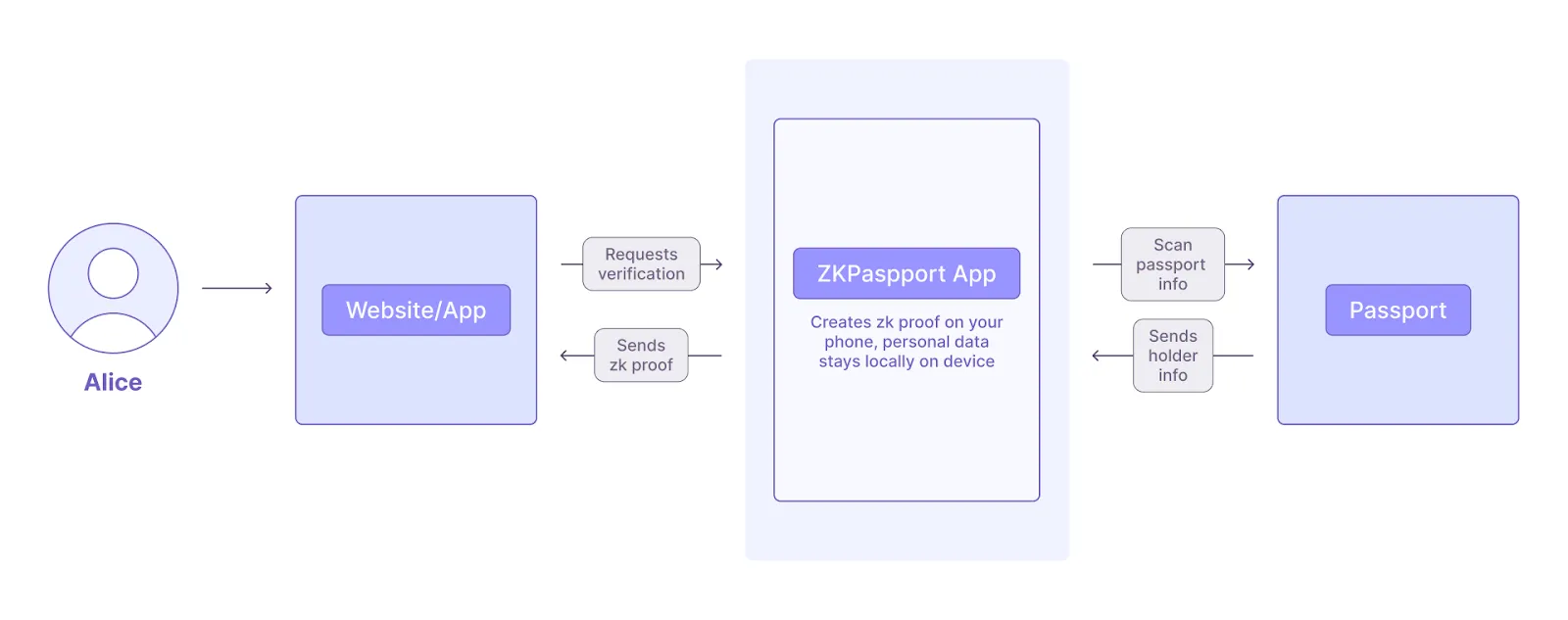
Once the user installs the ZKPassport app and scans their passport, the proof of identity is generated on the user's smartphone (client-side).
All the private data read from the NFC chip in the passport or ID is processed client-side and never leaves the smartphone (aka: only the user is aware of their data). Only this proof is sent to an app that has requested some information. The app can then verify the validity of the user’s age or nationality, all without actually seeing anything about the user other than what the user has authorized the app to see. In the case of age verification, the user may want to prove that they are over 18, so they’ll create a proof of this on their phone, and the requesting app is able to verify this information without knowing anything else about them.
For the Aztec Testnet, the network only needs to know that the user holds a valid passport, so no information is shared by the user other than “yes, I hold a valid passport or ID.”
This is a nascent and evolving technology, and various phone models, operating systems, and countries are still being optimized for. To ensure this works seamlessly, we’ll be selecting the first cohort of people who have already been running active validators on a rolling basis to help test ZKPassport and provide early feedback.
If someone successfully verifies that they are a valid passport holder, they will be added to a queue to enter the validator set. Once they are in line, they are guaranteed entry. The queue will enable an estimated additional 10% of the current set to be allowed in each day. For example, if 800 sequencers are currently in the set, 80 new sequencers will be allowed to join that day.
This allows existing operators to maintain control of the network in the event that bad actors enter, while dramatically increasing the number of new validators added compared to the current number.
With ZKPassport now live, the Aztec Testnet is better equipped to distinguish real users from bots, without compromising on privacy or decentralization.
This integration is already enabling more verified human node operators to join the validator set, and the network is ready to welcome more. By leveraging ZKPs and client-side proving, ZKPassport ensures that humanity checks are both secure and permissionless, bringing us closer to a decentralized future that doesn’t rely on trust in centralized authorities.
This is exciting not just for Aztec but for the broader ecosystem. As the network continues to grow and develop, participation must remain open to anyone acting in good faith, regardless of geography or background, while keeping out bots and other malicious actors. ZKPassport makes this possible.
We’re excited to see the community expand, powered by real people helping to build a more private, inclusive, and human Web3.
Stay up-to-date on Noir and Aztec by following Noir and Aztec on X.
Imagine an app that allows users to post private messages while proving they belong to an organization, without revealing their identity. Thanks to zero-knowledge proofs (ZKPs), it's now possible to protect the user’s identity through secure messaging, confidential voting, secured polling, and more. This development in privacy-preserving authentication creates powerful new ways for teams and individuals to communicate on the Internet while keeping aspects of their identity private.
Compared to Glassdoor, StealthNote is an app that allows users to post messages privately while proving they belong to a specific organization. Built with Noir, an open-source programming language for writing ZK programs, StealthNote utilizes ZKPs to prove ownership of a company email address, without revealing the particular email or other personal information.
To prove the particular domain email ownership, the app asks users to sign in using Google. This utilizes Google’s ‘Sign in with Google’ OAuth authorization. OAuth is usually used by external applications for user authorization and returns verified users’ data, such as name, email, and the organization’s domain.
However, using ‘Sign in with Google’ in a traditional way reveals all of the information about the person’s identity to the app. Furthermore, for an app where you want to allow the public to verify the information about a user, all of this information would be made public to the world. That’s where StealthNote steps in, enabling part of the returned user data to stay private (e.g. name and email) and part of it to be publicly verifiable (e.g. company domain).
When you "Sign in with Google" in a third-party app, Google returns some information about the user as a JSON Web Token (JWT) – a standard for sending information around the web.
JWTs are just formatted strings that contain a header (some info about the token), a payload (data about the user), and a signature to ensure the integrity and authenticity of the token:
Anyone can verify the authenticity of the above data by verifying that the JWT was signed by Google using their public key.
In the case of StealthNote, we want to authorize the user and prove that they sent a particular message. To make this possible, custom information is added to the JWT token payload – a hashed message. With this additional field, the JWT becomes a digitally signed proof that a particular user sent that exact message.
You can share the message and the JWT with someone and convince them that the message was sent by someone in the company. However, this would require sharing the whole JWT, which includes your name and email, exposing who the sender is. So, how does StealthNote protect this information?
They used a ZK-programming language, Noir, with the following goals in mind:
The payload and the signature are kept private, meaning they stay on the user’s device and never need to be revealed, while the hashed message, the domain, and the JWT public key are public. The ZKP is generated in the browser, and no private data ever leaves the user's device.

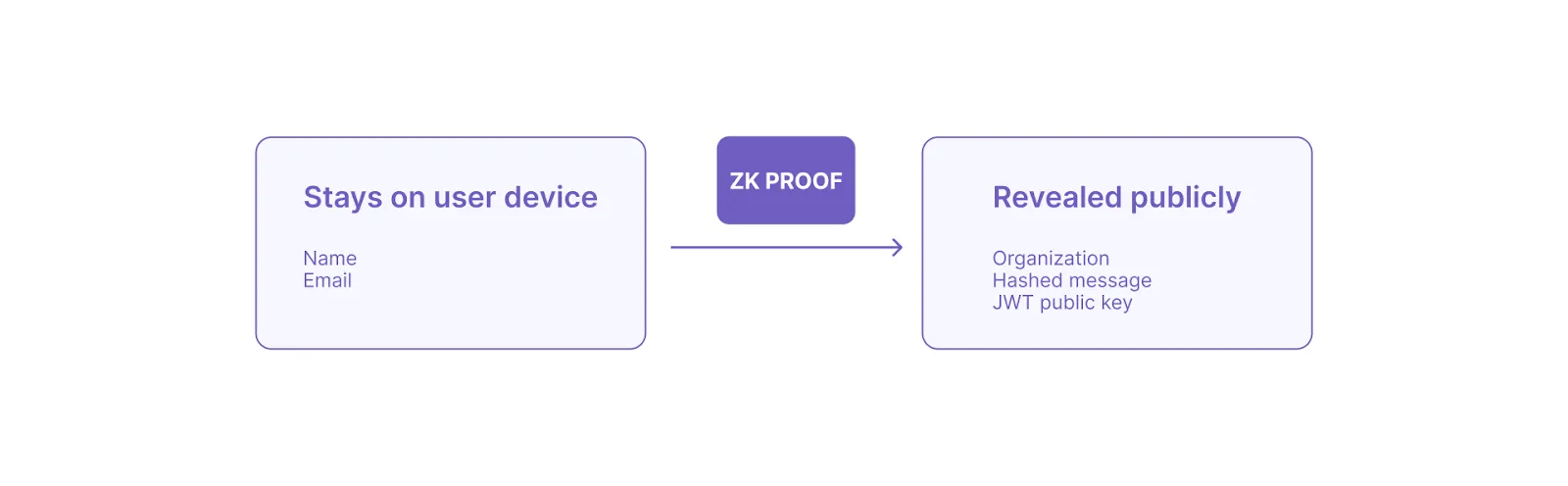
By executing the program with Noir and generating a proof, the prover (the user who is posting a message) proves that they can generate a JWT signed by some particular public key, and it contains an email field in the payload with the given domain.
When the message is sent to the StealthNote server, the server verifies that the proof is valid as per the StealthNote circuit and validates that the public key in the proof is the same as Google's public key.
Once both checks pass, the server inserts the proof into the database, which then appears in the feed visible for other users. Other users can also verify the proof in the browser. The role of the server is to act as a data storage layer.
Stay up-to-date on Noir and Aztec by following Noir and Aztec on X.
The global political discourse around protecting underage internet users is heating up as lawmakers struggle to achieve safe and secure internet access for minors without imposing on civil liberties.
The European Parliament’s global estimates reveal that one in three children is an internet user, and one in three internet users is under 18. As digital consumption by minors grows, policymakers worldwide are pushing for more stringent age verification laws. However, these efforts are increasingly met with legal and constitutional challenges.
This report explores the potential behind zero-knowledge proof (“ZKP”) identities (“ZKIs”) as an innovative solution for online age verification, offering the dual advantage of enabling robust identity verification while safeguarding personal information.
Click here to read the full report.
On May 1st, 2025, Aztec Public Testnet went live.
Within the first 24 hours, over 20k users visited the Aztec Playground and started to send transactions on testnet. Additionally, 10 apps launched live on the testnet, including wallets, block explorers, and private DeFi and NFT marketplaces. Launching a decentralized testnet poses significant challenges, and we’re proud that the network has continued to run despite high levels of congestion that led to slow block production for a period of time.
Around 6 hours after announcing the network launch, more than 150 sequencers had joined the validator set to sequence transactions and propose blocks for the network. 500+ additional full nodes were spun up by node operators participating in our Discord community. These sequencers were flooded with over 5k transactions before block production slowed. Let’s dive into why block production slowed down.
On Aztec, an epoch is a group of 32 blocks that are rolled up for settlement on Ethereum. Leading up to the slowdown of block production, there were entire epochs with full blocks (8 transactions, or 0.2TPS) in every slot. The sequencers were building blocks and absorbing the demand for blockspace from users of the Aztec playground, and there was a build up of 100s of pending transactions in sequencer mempools.
Issues arose when these transactions started to exceed the mempool size, which was configured to hold only 100mb or about 700 transactions.
As many new validators were brought through the funnel and started to come online, the mempools of existing validators (already full at 700 transactions) and new ones (at 0 transactions) diverged significantly. When earlier validators proposed blocks, newer validators didn't have the transactions and could not attest to blocks because the request/response protocol wasn't aggressive enough. When newer validators made proposals, earlier validators didn't have transactions (their mempools were full), so they could not attest to blocks.
New validators then started to build up pending transactions. When validators with full mempools requested missing transactions from peers, they would evict existing transactions from their mempools (mempool is at max memory) based on priority fee. All transactions had default fee settings, so validators were randomly ejecting transactions and were not doing so in lockstep (different validators ejected different transactions). For a little over an hour, the mempools diverged significantly from each other, and block production slowed down to about 20% of the expected rate.
In order to stop the mempool from ejecting transactions, the p2p mempool size was increased. By increasing the mempool size, the likelihood of needing to evict transactions that might soon appear in proposals is reduced. This increases the chances that sequencers already have the necessary transactions locally when they receive a block proposal. As a result, more validators are able to attest to proposals, allowing blocks to be finalized more reliably. Once blocks are included on L1, their transactions are evicted from the mempool. So over time, as more blocks are finalized and transactions are mined, the mempool naturally shrinks and the network will recover on its own.
If you are interested in running a sequencer node visit the sequencer page. Stay up-to-date on Noir and Aztec by following Noir and Aztec on X.